1. 서론
-RocksDB는 big data 처리를 관리하기 위해 만들어진 key-value engine이다.
-RocksDB는 LSM(로그 구조 병합 트리)를 기반으로 C++ library 형태로 제공되며 Facebook에서 Google의 LevelDB를 기반으로 제작되어 flash drive에 data를 저장하는데 적합하다.
-RocksDB는 open source software로 memory,flash memory,hard disk 등 여러 환경에서 실행 가능하며, 여러 설정을 조정할 수 있다.
2. 목표
a. point lookup 및 range scan이 포함 된 key-value storage
b. 빠른 저장에 최적화 (예 : Flash memory 및 RAM)
c. 완전한 프로덕션 지원을 제공하는 서버 측 데이터베이스
d. CPU core 갯수 및 storage IOPs에 따라 선형 적으로 확장
3. 구조 및 기본 작업
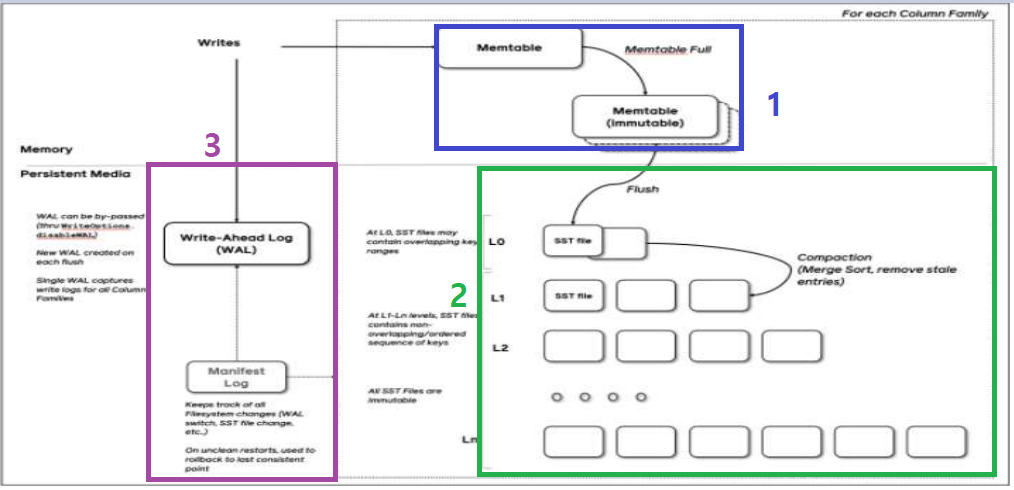
a. Memtable -1
- Memory 영역의 table 이며, Data의 삽입이 발생하게 되면 먼저 key와 value 값이 저장되는 곳이다. Memtable이 가득차게 되면 Memtable은 Data 변경이 불가능한 Immutable Memtable로 변경된 후, Immutable Memtable은 Level 0의 SST file로 변경 되어 정렬된 상태로 Disk 영역으로 flush 되는 특징을 갖는다.
b. SST file -2
- Disk storage에 위치한 data file로, key-value를 저장하고 있으며, 각 key 값들은 level에 따라 정렬되어 저장되어 있다. Level 0 의 SST File의 갯수가 초과되면 해당 File은 하위 레벨에서 중복된 key 값을 갖는 파일과 병합 정렬되어 내려가게 되는 특징을 갖는다. 따라서 Level 1 이상의 SST file들은 모두 정렬되어 있다.
c. Log file -3
- Storage에 위치하여, Data의 Recovery를 위한 목적으로 존재하여 Memory의 Data가 날아가게 되어도, Log 기록을 남겨 Data의 Integrity를 높히기 위한 목적으로 존재한다.
d. 기본 작업
- Get(key): 해당 key에 맞는 value를 얻어 오는 작업
- Put(key,value): key-value를 database에 삽입하여 주는 작업
- Delete(key): 해당 key의 value를 삭제 하는 작업
- Newlterator(): 특정 범위를 range scan 할 수 있도록 해주는 작업
4. 특징
a. Compaction
- Update를 위한 작업으로, 이미 존재하는 key-value들이 overlapping 되는것을 막아준다. compaction은 background 작업을 통해 이루어지므로, 병렬적으로 처리 가능하게 되고 위의 SST File들 처럼 중복된 값들을 병합 정렬하는 작업을을 compaction 이라고 한다. compaction에는 Tiered compaction, Leveled compaction, FIFO compaction 등이 있다.
b. WAL(Write-Ahead-Log)
- WAL은 매 update 마다 disk와 memtable에서의 작업들을 기록(Log)한다. 이는 예기치 못한 상황으로 memory가 날라갔을 때 복구를 해주기 위한 작업으로 memtable이 성공적으로 disk에 저장되면 WAL은 삭제된다.
c. LSM(Log Structured Merge)- Tree
- LSM Tree는 In-place-update가 되지 않고, append를 사용한다.
- Write 시에는 skiplist 자료구조를 사용하여 입력되는 data들의 순서를 유지하여주어 Multithreaded System 환경에서 유용하다.
*skiplist: 정렬된 linked list 에서 빠른 검색, 삽입, 삭제등을 가능하게 해주는 자료구조이며 시간복잡도는 O(logN) 이다.
- Read 시에는 Memory-Immutable memory-Disk 순서로 읽는다.
d. Bloom filter
- 특정 원소가 집합에 속해 있는지 검사할 때 유용한 확률적 자료구조이다.
- 어떠한 원소가 집합에 포함되어 있지 않은데, 포함되어있다는 오류가 발생할 수는 있으나 원소가 포함되어있는데 포함되어있지 않다는 오류는 발생하지 않는다는것이 특징이다.
- Bloom filter는 특정크기의 비트를 갖는 비트 배열 구조로, 특정 값의 집합에 속하는 여부를 판단 할때 해당 값의 특정 해시값의 bit가 0이면 속해있지 않다고 판단한다.
e. Gets, Iterators, Puts
- key-value는 byte stream으로 이루어져 있으며 크기에 제한이 없다. Get은 이러한 key를 통해 value를 가져올 수 있도록 하여준다.
- Iterator들은 정렬된 data에서 특정 key를 통해 그 key를 기점으로 일정 범위를 탐색하는 range sacn이 가능하도록 하여준다. 특히 RocksDB는 key 범위에 대해 key-prefix내에서 스캔하므로 완전한 탐색을 하지 않아 모든 데이터 파일을 탐색하지 않아 효율적인 range scan이 가능하다.
- RocksDB는 삽입시에 이전 값이 존재한다면 이전 값은 덮어 쓰여지게 된다.
f. Avoiding Delay
- Background 작업들을 통해, memtable에서 disk의 flush 및 compaction 작업들을 병렬적으로 처리 할 수 있도록 하여 작업들이 지연되는것을 피하도록 해준다.
g. Read-Only Mode
- Read-Only Mode를 통해 해당 Database는 Read만 가능하도록 하여, Lock으로 인해 성능이 지연되는 것을 예방하여 읽기 성능을 향상 시켜 줄 수 있게 된다.
참조링크
1. https://github.com/facebook/rocksdb/wiki
2. http://rocksdb.blogspot.com/2013/11/the-history-of-rocksdb.html
'Back End > DataBase' 카테고리의 다른 글
| [ORM] ORM이란? (0) | 2023.05.31 |
|---|---|
| [Mysql] 쿠팡이츠(Coupang Eats) ERD 설계 (0) | 2021.10.01 |

